No dobrze, pora szturchnąć tego potwora. Bo jeszcze nie ma żadnego zapisu na forum w jego kwestii. Można by zebrać jakieś wymagania, alternatywy, oraz potencjalne rozwiązania.
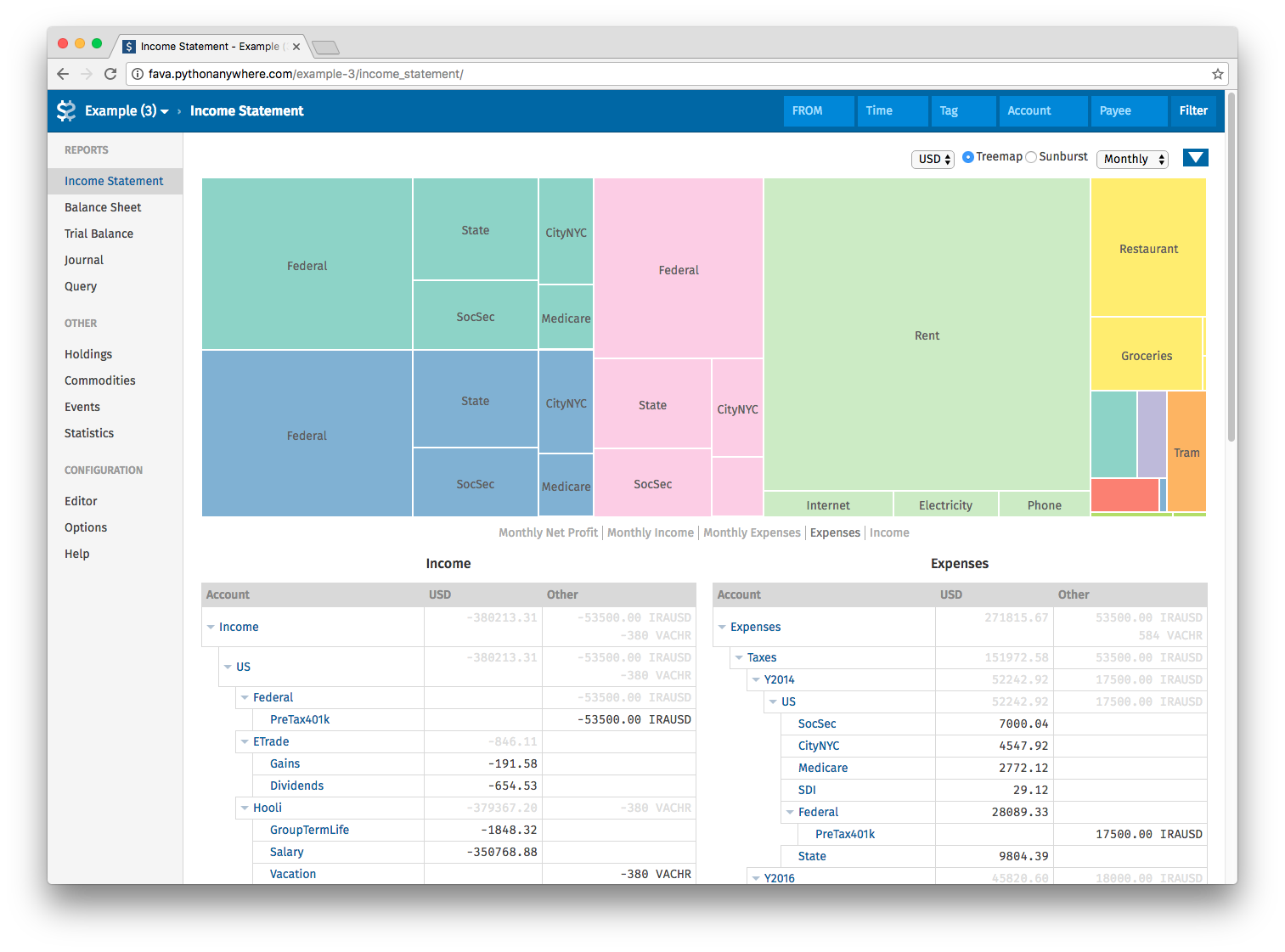
Ponieważ pisanie UI jest absolutnie bezsensu gdy istnieje fava dla beancount, celowałbym w jej wykorzystanie. Wygląda przyzwoicie, i jest chyba najpotężniejszym narzędziem które znam.
https://beancount.github.io/fava/
1 polubienie
Wymagania
- MEM-001 system musi śledzić wpływające składki w czasie
- MEM-002 każdy użytkownik musi mieć możliwość sprawdzenia jego prywatnego statusu opłacenia składek
- MEM-100 system musi umożliwiać dodawanie danych ręcznie
- MEM-101 system powinien udostępniać API do dodawania danych
- MEM-102 system powinien mieć możliwość przyjmowania danych z różnych źródeł
- MEM-103 te same transakcje z różnych źródeł nie mogą się duplikować
- MEM-104 system powinien korzystać z formatu pośredniego, format pośredni powinien mieć standard i być wspierany
- MEM-200 wielkość i czas naliczania składki musi być parametryzowalny
- MEM-201 wielkość i czas naliczania składki powinno dać się zmienić w trakcie działania programu bez naruszania poprzednich transakcji
MVP
Pokazać kto w poprzednim miesiącu zapłacił składkę
Trzeba mimo wszystko przytoczyć poprzednie starania
1 polubienie
Na początek to pewnie dobrze byłoby ogarnąć https://www.openbankingbnpparibas.pl/documentation/nextswagger
1 polubienie
Obawiam się, że w wielu przypadkach znajduje się to za paywallem. Trzeba by pomęczyć banki, ale przeważnie otwierają to jedynie dla innych instytucji.
Ale stowarzyszenie jest instytucja 
Więc jeśli każde stow. byłoby w stanie się dobrać do tych danych. To ten odpowiednio napisany system składkowy można by zaaplikować do innych stowarzyszeń w Polsce. A z tego co wiem, wszędzie problemy są podobne jeśli chodzi o składki.
Nie wiem jak w Waszym banku, ale w mBanku istnieje instytucja codziennych powiadomień e-mail. O tyle fajne, że jest to “pasywne” - nie trzeba się nigdzie logować, wystarczy napisać skrypt sprawdzający maila. W HSŁ robi to nam ksiemgowy: https://github.com/hakierspejs/ksiemgowy
2 polubienia
Nasze BNP podaje jedynie potwierdzenia przelewów wychodzących. Ale to też jest jakieś źródło danych. Dodam wymaganie, na rozróżnienie transakcji z różnych źródeł.
API bankowe wymagają rejestracji w jakimś większym rejestrze, a tam z kolei trzeba być instytucja finansowa, czy coś w ten deseń. Jak to wprowadzali, to się ucieszyłem, że fajnie zintegruję sobie płatności w sklepie przez kulturalne API, a potem odbiłem się od ściany ;).
Mam bota który loguje się na konto w mBanku i ściąga listę transakcji w jakimś cywilizowanym formacie. Do każdego innego banku pewnie też da się coś takiego napisać.
E/w są jakieś Dotpay’e i inne takie, biorą po 1% prowizji, ale udostępniają kulturalne API.
1 polubienie
No właśnie sporo osób tak właśnie robi. Ja chciałbym umożliwić generyczny interfejs na różne stopnie automatyzacji. Od ręcznego wklepywania, przez dziwne hacki, po prawilne API.
Mnie głównie interesuje co dalej z tymi danymi. Pewnie znowu spróbuję wcisnąć event sourcing, bo nawet @korposzczur chciał to zaimplementować w pierwotnej idei.
A to ciekawostka
i jeszcze inny standard
XBRL ma nawet wsparcie Unii Europejskiej. OFX to dosyć stary format, ale ma sporo bibliotek. Przynajmniej na GH.
Faktycznie…
Przedsiębiorca – inny niż Bank podmiot prowadzący zgodnie z Przepisami działalność gospodarczą w zakresie świadczenia usługi PIS, usługi AIS lub usługi CAF posiadający zezwolenie na świadczenie ww. usług płatniczych, bądź ubiegający się o taki status, który złożył do właściwego organu nadzoru wniosek o stosowne zezwolenie na świadczenie ww. usług płatniczych;
To z regulaminu BNP ![]()
@korposzczur @psuwala zastanawiam się co w naszym przypadku jest agregatem. Chciałem przerobić ten przykład, ale ciężko mi to zaaplikować:
https://eventsourcing.readthedocs.io/en/stable/topics/examples/bank-accounts.html
Już mówię dlaczego:
- Nie chcę przypisywać konta (to relacja many-to-many) do użytkownika, chce pobierać dane z tytułu przelewu.
- Co jeśli zmieni się tytuł przelewu, musiałbym to jakoś obsłużyć.
- Zakładam takie akcje, jak rozdzielanie i łączenie użytkowników. Czy to nie narusza unikalnego id?
Chociaż ID agregatu niekoniecznie musi być powiązane z czymś konkretnym w transakcji, np ID samej transakcji. Może potrzebuję odpowiednich pytań.
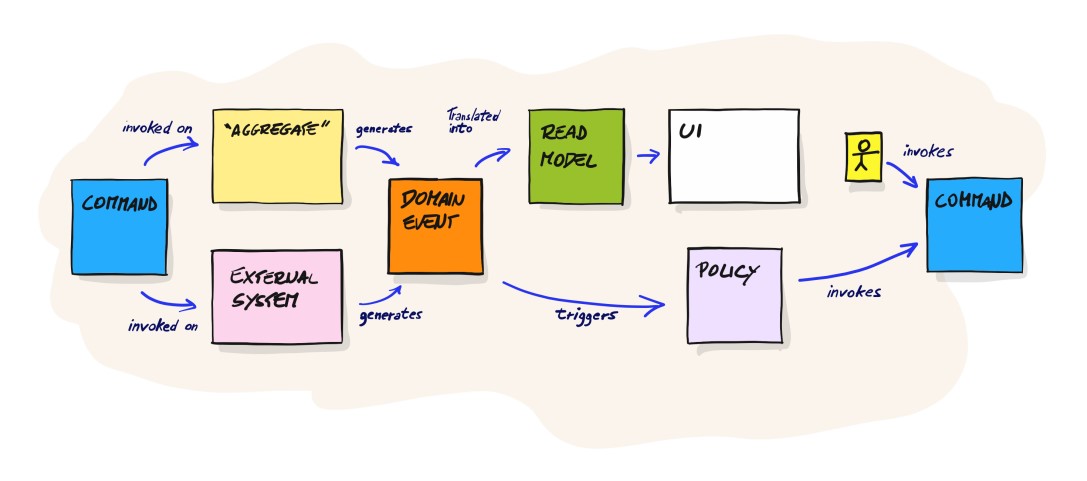
Zrób mi liste commands jakie chcesz mieć, to sa wlasnie te use case’y. Prosta liste nazw samowyjasniajacych sie.
Jest TransactionLink. Trzeba sie ich spytac jakie maja uslugi.
EDIT:
https://www.transactionlink.io/
Ja chcę się do nich aplikować, ale jeszcze nie wiem czy chcę.
Ale właśnie mają być taką warstwą abstrakcji do kont bankowych.
Agregat nie musi być jakoś duży, jeżeli nie masz jakichś ważnych reguł, które musi spełniać.
Oprócz relacyjności, to dla mnie ważniejsze jest, by operacje w nim wykonywane były w transakcji.
Je po przeczytaniu książki Implementing DDD mam myślenie bardziej eventowe.
Stowrzyłbym parę bounded kontekstów:
- Members
- Banking
Members
Aggregate
Zawiera MemberAggregate, który zawiera metody:
- increaseAccountBalance
- decreaseAccountBalance
- getBalance
- getName
- getId
Policy
- on IncreaseAccountBalanceEvent(MemberId, Amount) then Member(MemberId).increaseAccountBalance(Amount)
- on DecreaseAccountBalanceEvent(MemberId, Amount) then Member(MemberId).decreaseAccountBalance(Amount)
Banking
Tutaj w sumie chcemy przechowywać tylko zasady, które stwierdzą jaki przelew prowadzi do jakiego członka. Nawet nie wiem czy chcemy per se to robić za pomocą DDD.
Ja widzę system, który na wejściu dostaje tego typu commandsy:
Commands
- AddMatcher(TitlePattern, MemberId)
- RemoveMatcher(MatcherId)
- NewTransaction(TransactionDTO)
jakoś je tam procesuje i wypluwa
Events
IncreaseAccountBalanceEvent(MemberId, Amount)
DecreaseAccountBalanceEvent(MemberId, Amount)
Czy coś takiego.
Zastanawiałem się nad tym kiedyś właśnie pod kątem systemu składkowego i jeszcze niezorientowany próbowałem dostać do tego dostęp. Mój bank (Millennium) nie udostępnia nawet publicznie dokumentacji do swojej implementacji tego API. Wniosek można było złożyć chyba tylko jako DG. Dostęp do API wymaga licencji (czy innego pozwolenia) od KNF, same koszty urzędowe wynoszą chyba ponad 600 zł. Komunikacja z bankami wymaga też posiadania specjalnego certyfikatu TLS, który kosztuje chyba w okolicach 1000 zł. Nie są to kwoty zaporowe, ale i tak raczej nie warto. Poza tym nie widziałem chyba, żeby z tego API korzystał ktokolwiek poza bankami (o użyciu takich funkcji jak zlecanie płatności nawet nie słyszałem), więc i tak jest pewnie bardzo ciężko przejść przez jakąś weryfikację, która musi się odbywać po drodze.
Ubolewam nad tym, ale nie jest to narzędzie dla prostych śmiertelników.
A teraz dlaczego w ogóle odzywam się w tym wątku.
Nie wiem skąd się wziął pomysł tego event sourcingu, zakładam, że wyszedł w trakcie jakichś rozmów na żywo.
Do realizacji którego z tych wymagań potrzebujemy event sourcingu? Nie rozumiem zupełnie potrzeby bawienia się w tak wysokopoziomowe abstrakcje. Ten system nie ma nawtet żadnych wymagań związanych ze skalowaniem.
Wystarczy zrobić prostą apkę w Django (to jest konkretna propozycja, dlaczego wyjdzie zaraz).
Użytkownicy i logowanie dostajemy za darmo. Wystarczy zrobić kilka tabel (w zasadzie do MVP przechowywać wystarczy tylko członków stowarzyszenia i przelewy przychodzące, ewentualnie spięte dodatkowo kontami bankowymi bo konta mogą się zmieniać).
Za darmo dostajemy też panel admina, w którym można to wszystko modyfikować bez ręcznego grzebania w bazie danych albo pisania samemu do wszystkiego interfejsów (a wierzcie mi, będzie to trzeba robić, prędzej czy później ktoś wyśle przelew ze złą nazwą albo coś w tym stylu).
Dalej jest API, które pozwoli na dodawanie nowych wpłat i pobieranie informacji o tym kto zalega ze składkami (jeśli np. chcemy zrobić bota, który będzie o tym przypominał). Tutaj bardzo istotne będzie odpowiednie ograniczenie dostępu do API (klucze, ograniczony zakres dostępu).
Do tego dopinamy skrypt wrzucony w crona, który będzie pobierał informacje o transakcjach. Ewentualnie może to być też ręczny skrypt parsujący dane z PDF jeśli inaczej się nie da.
Zobaczmy jak to się ma do naszych wymagań.
To jest bardzo szerokie, ale z opisu wyżej chyba widać jak to będzie działać.
Encje użytkowników są połączone z encjami członków, normalny użytkownik może wejść tylko na stronę, na której są tylko jego składki.
Admin Django i/lub skrypt do manualnego uruchamiania.
O API też już było.
Kwestia integracji korzystających z API. Sam punkt jest mało konkretny i nie podaje źródeł, mi ciężko wyobrazić sobie więcej niż jedno.
Patrz wyżej, nie wiem jak mogłoby do tego dojść, ale API może odrzucać tworzenie wpisów o identyfikatorze, który już istnieje (np. trójka: członek, źródło, czas.
Nie wiem co znaczy “być wspierany”, ale całą resztę spełnia JSON jakiego spodziewać się będzie API.
Jest za to kilka problemów, które wybiegają poza wysokopoziomowy design:
- system będzie przechowywał wrażliwe dane, dlatego powinien być możliwie prosty, żeby dało się go audytować;
- nie mamy oczywistego sposobu pozyskiwania danych do systemu, bez PoC tej części nie ma sensu pisać czegokolwiek innego (chyba, że zależy nam na czymś co będzie wyglądało ładniej niż Excel ale nadal wymagało manualnego dodawania danych);
- poprawne mapowanie metadanych przelewu (tytuł, nadawca, numer konta nadawcy, data przelewu) czy nawet samej kwoty (różni członkowie płacą regularnie inną) na składkę w systemie jest cholernie trudnym problemem, który może okazać się trudniejszy niż wymuszenie na członkach regularnych przelewów o ściśle określonych tytułach.
Z całym szacunkiem @psuwala, @not7cd, ale dopóki nie rozwiążemy tych problemów to bawienie się w modne skomplikowane wzorce projektowe i projektowanie API jest sztuką dla sztuki i ma znikomą wartość.